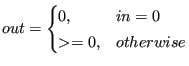Next: Component Based Objects Up: Data-Oriented Design Previous: Relational Databases Contents
If you saw there weren't any apples in stock, would you still haggle over their price?
Existential processing attempts to provide a way to remove unnecessary querying about whether or not to process your data. In most software, there are checks for NULL and queries to make sure the objects are in a valid state before work is started. What if you could always guarantee your pointers were not null? What if you were able to trust that your objects were in a valid state, and should always be processed?
In this chapter, a dynamic runtime polymorphism technique is shown that can work with the data-oriented design methodology. It is not the only way to implement data-oriented design friendly runtime polymorphism, but was the first solution discovered by the author, and fits well with other game development technologies, such as components and compute shaders.
When studying software engineering you may find references to cyclomatic complexity or conditional complexity. This is a complexity metric providing a numeric representation of the complexity of programs and is used in analysing large-scale software projects. Cyclomatic complexity concerns itself only with flow control. The formula, summarised for our purposes, is one (1) plus the number of conditionals present in the system being analysed. That means for any system it starts at one, and for each if, while, for, and do-while, we add one. We also add one per path in a switch statement excluding the default case if present.
Under the hood, if we consider how a virtual call works, that is, a lookup in a function pointer table followed by a branch into the class method, we can see that a virtual call is effectively just as complex as a switch statement. Counting the flow control statements is more difficult in a virtual call because to know the complexity value, you have to know the number of possible methods that can fulfil the request. In the case of a virtual call, you have to count the number of overrides to a base virtual call. If the base is pure-virtual, then you may subtract one from the complexity. However, if you don't have access to all the code that is running, which can be possible in the case of dynamically loaded libraries, then the number of different potential code paths increases by an unknown amount. This hidden or obscured complexity is necessary to allow third party libraries to interface with the core process, but requires a level of trust that implies no single part of the process is ever going to be thoroughly tested.
This kind of complexity is commonly called control flow complexity. There is another form of complexity inherent in software, and that is the complexity of state. In the paper Out of the Tar Pit[#!TarPit!#], it's concluded that the aspect of software which causes the most complexity is state. The paper continues and presents a solution which attempts to minimise what it calls accidental state, that is, state which is required by the software to do its job, but not directly required by the problem being solved. The solution also attempts to abolish any state introduced merely to support a programming style.
We use flow control to change state, and state changes what is executed in our programs. In most cases flow control is put in for one of two reasons: to solve the problem presented (which is equivalent to the essential state in Out of the Tar Pit), and to help with the implementation of the solution (which is equivalent to the accidental state).
Essential control is when we need to implement the design, a gameplay feature which has to happen when some conditions are met, such as jumping when the jump button is pressed or autosaving at a save checkpoint when the savedata is dirty, or a timer has run out.
Accidental control is non-essential to the program from the point of view of the person using it, but could be foundation work, making it critical for successful program creation. This type of control complexity is itself generally split into two forms. The first form is structural, such as to support a programming paradigm, to provide performance improvements, or to drive an algorithm. The second form is defensive programming or developer helpers such as reference counting or garbage collection. These techniques increase complexity where functions operating on the data aren't sure the data exists, or is making sure bounds are observed. In practice, you will find this kind of control complexity when using containers and other structures, control flow is going to be in the form of bounds checks and ensuring data has not gone out of scope. Garbage collection adds complexity. In many languages, there are few guarantees about how and when it will happen. This also means it can be hard to reason about object lifetimes. Because of a tendency to ignore memory allocations early in development when working with these languages, it can be very hard to fix memory leaks closer to shipping dates. Garbage collection in unmanaged languages is easier to handle, as reference counts can more easily be interrogated, but also due to the fact that unmanaged languages generally allocate less often in the first place.
What classes of issues do we suffer with high complexity programs? Analysing the complexity of a system helps us understand how difficult it is to test, and in turn, how hard it is to debug. Some issues can be classified as being in an unexpected state, and then having no way forward. Others can be classified as having bad state, and then exhibiting unexpected behaviour due to reacting to this invalid data. Yet others can be classified as performance problems, not just correctness, and these issues, though somewhat disregarded by a large amount of academic literature, are costly in practice and usually come from complex dependencies of state.
For example, the complexity caused by performance techniques such as caching, are issues of complexity of state. The CPU cache is in a state, and not being aware of it, and not working with the expected state in mind, leads to issues of poor or inconsistent performance.
Much of the time, the difficulty we have in debugging comes from not fully observing all the flow control points, assuming one route has been taken when it hasn't. When programs do what they are told, and not what we mean, they will have entered into a state we had not expected or prepared for.
With runtime polymorphism using virtual calls, the likelihood of that happening can dramatically increase as we cannot be sure we know all the different ways the code can branch until we either litter the code with logging, or step through in a debugger to see where it goes at run-time.
In real-world cases of game development, the most common use of an explicit flow control statement would appear to be in the non-essential set. Where defensive programming is being practiced, many of the flow control statements are just to stop crashes. There are fail-safes for out of bounds accesses, protection from pointers being NULL, and defenses against other exceptional cases that would bring the program to a halt. It's pleasing to note, GitHub contains plenty of high quality C++ source-code that bucks this trend, preferring to work with reference types, or with value types where possible. In game development, another common form of flow control is looping. Though these are numerous, most compilers can spot them, and have good optimisations for these and do a very good job of removing condition checks that aren't necessary. The final inessential but common flow control comes from polymorphic calls, which can be helpful in implementing some of the gameplay logic, but mostly are there to entertain the do-more-with-less-code development model partially enforced in the object-oriented approach to writing games.
Essential game design originating flow control doesn't appear very often in profiles as causes of branching, as all the supporting code is run far more frequently. This can lead to an underappreciation of the effect each conditional has on the performance of the software. Code that does use a conditional to implement AI or handle character movement, or decide on when to load a level, will be calling down into systems which are full of loops and tree traversals, or bounds checks on arrays they are accessing in order to return the data upon which the game is going to produce the boolean value to finally drive the side of the if to which it will fall through. That is, when the rest of your code-base is slow, it's hard to validate writing fast code for any one task. It's hard to tell what additional costs you're adding on.
If we decide the elimination of control flow is a goal worthy of consideration, then we must begin to understand what control flow operations we can eliminate. If we begin our attempt to eliminate control flow by looking at defensive programming, we can try to keep our working set of data as a collections of arrays. This way we can guarantee none of our data will be NULL. That one step alone may eliminate many of our flow control statements. It won't get rid of loops, but as long as they are loops over data running a pure functional style transform, then there are no side-effects to worry about, and it will be easier to reason about.3.1
The inherent flow control in a virtual call is avoidable, as it is a fact that many programs were written in a non-object-oriented style. Without virtuals, we can rely on switch statements. Without those, we can rely on function pointer tables. Without those, we can have a long sequence of ifs. There are many ways to implement runtime polymorphism. It is also possible to maintain that if you don't have an explicit type, you don't need to switch on it, so if you can eradicate the object-oriented approach to solving the problem, those flow control statements go away completely.
When we get to the control flow in gameplay logic, we find there is no simple way to eradicate it. This is not a terrible thing to worry about, as the gameplay logic is as close to essential complexity as we can get when it comes to game development.
Reducing the number of conditionals, and thus reducing the cyclomatic complexity on such a scale is a benefit which cannot be overlooked, but it is one that comes with a cost. The reason we are able to get rid of the check for NULL is that we will have our data in a format that doesn't allow for NULL at all. This inflexibility will prove to be a benefit, but it requires a new way of processing our entities.
Where once we would have an object instance for an area in a game, and we would interrogate it for exits that take us to other areas, now we look into a structure that only contains links between areas, and filter by the area we are in. This reversal of ownership can be a massive benefit in debugging, but can sometimes appear backward when all you want to do is find out what exits are available to get out of an area.
If you've ever worked with shopping lists or to-do lists, you'll know how much more efficient you can be when you have a definite list of things to purchase or complete. It's very easy to make a list, and adding to it is easy as well. If you're going shopping, it's very hard to think what might be missing from your house in order to get what you need. If you're the type that tries to plan meals, then a list is nigh on essential as you figure out ingredients and then tally up the number of tins of tomatoes, or other ingredients you need to last through all the meals you have planned. If you have a to-do list and a calendar, you know who is coming and what needs to be done to prepare for them. You know how many extra mouths need feeding, how much food and drink you need to buy, and how much laundry you need done to make enough beds for the visitors.
To-do lists are great because you can set an end goal and then add in subtasks that make a large and long distant goal seem more doable. Adding in estimates can provide a little urgency that is usually missing when the deadline is so far away. Many companies use software to support tracking of tasks, and this software often comes with features allowing the producers to determine critical paths, expected developer hours required, and sometimes even the balance of skills required to complete a project. Not using this kind of software is often a sign that a company isn't overly concerned with efficiency, or waste. If you're concerned about efficiency and waste in your program, lists of tasks seem like a good way to start analysing where the costs are coming from. If you keep track of these lists by logging them, you can look at the data and see the general shape of the processing your software is performing. Without this, it can be difficult to tell where the real bottlenecks are, as it might not be the processing that is the problem, but the requirement to process data itself which has gotten out of hand.
When your program is running, if you don't give it homogeneous lists to work
with, but instead let it do whatever comes up next, it will be inefficient and
have irregular or lumpy frame timings. Inefficiency of hardware utilisation
often comes from unpredictable processing. In the
case of large arrays of pointers to heterogeneous classes all being called with
an update() function, you can hit high amounts of data dependency
which leads to misses in both data and instruction caches. See chapter
![]() for more details on why.
for more details on why.
Slowness also comes from not being able to see how much work needs to be done, and therefore not being able to prioritise or scale the work to fit what is possible within the given time-frame. Without a to-do list, and an ability to estimate the amount of time each task will take, it is difficult to decide the best course of action to take in order to reduce overhead while maintaining feedback to the user.
Object-oriented programming works very well when there are few patterns in the way the program runs. When either the program is working with only a small amount of data, or when the data is incredibly heterogeneous, to the point that there are as many classes of things as there are things.
Irregular frame timings can often be blamed on not being able to act on distant goals ahead of time. If you, as a developer, know you have to load the assets for a new island when a player ventures into the seas around it, the streaming system can be told to drag in any data necessary. This could also be for a room and the rooms beyond. It could be for a cave or dungeon when the player is within sight of the entrance. We consider this kind of preemptive streaming of data to be a special case and invent systems to provide this level of forethought. Relying on humans, or even level-designers, to link these together is prone to error. In many cases, there are chains of dependencies that can be missed without an automated check. The reason we cannot make systems self-aware enough to preload themselves is that we don't have a common language to describe temporal dependencies.
In many games, we stream things in with explicit triggers, but there is often no such system for many of the other game elements. It's virtually unheard of for an AI to pathfind to some goal because there might soon be a need to head that way. The closest would be for the developer to pre-populate a navigation map so coarse grain pathing can be completed swiftly.
There's also the problem of depth of preemptive work. Consider the problem of a small room, built as a separate asset, a waiting room with two doors near each other, both leading to large, but different maps. When the player gets near the door to the waiting room in map A, that little room can be preemptively streamed in. However, in many engines, map B won't be streamed in, as the locality of map B to map A is hidden behind the logical layer of the waiting room.
It's also not commonplace to find a physics system doing look ahead to see if a collision has happened in the future in order to start doing further work. It might be possible to do a more complex breakup simulation if it were more aware.
If you let your game generate to-do lists, shopping lists, distant goals, and allow for preventative measures by forward-thinking, then you can simplify your task as a coder into prioritising goals and effects, or writing code that generates priorities at runtime. You can start to think about how to chain those dependencies to solve the waiting room problem. You can begin to preempt all types of processing.
Existential processing is related to to-do lists. When you process every element in a homogeneous set of data, you know you are processing every element the same way. You are running the same instructions for every element in that set. There is no definite requirement for the output in this specification, however, it usually comes down to one of three types of operation: a filter, a mutation, or an emission. A mutation is a one to one manipulation of the data, it takes incoming data and some constants that are set up before the transform, and produces one and only one element for each input element. A filter takes incoming data, again with some constants set up before the transform, and produces one element or zero elements for each input element. An emission is a manipulation of the incoming data that can produce multiple output elements. Just like the other two transforms, an emission can use constants, but there is no guaranteed size of the output table; it can produce anywhere between zero and infinity elements.
A fourth, and final form, is not really a manipulation of data, but is often part of a transform pipeline, and that is the generator. A generator takes no input data, but merely produces output based on the constants set up. When working with compute shaders, you might come across this as a function that merely clears out an array to zero, one, or an ascending sequence.
These categories can help you decide what data structure you will use to store the elements in your arrays, and whether you even need a structure, or you should instead pipe data from one stage to another without it touching down on an intermediate buffer.
Every CPU can efficiently handle running processing kernels over homogeneous sets of data, that is, doing the same operation over and over again over contiguous data. When there is no global state, no accumulator, it is proven to be parallelisable. Examples can be given from existing technologies such as map-reduce and simple compute shaders, as to how to go about building real work applications within these restrictions. Stateless transforms also commit no crimes that prevent them from being used within distributed processing technologies. Erlang relies on these guarantees of being side-effect free to enable not just thread safe processing or interprocess safe processing, but distributed computing safe processing. Stateless transforms of stateful data are highly robust and deeply parallelisable.
Within the processing of each element, that is for each datum operated on by the transform kernel, it is fair to use control flow. Almost all compilers should be able to reduce simple local value branch instructions into a platform's preferred branch-free representation, such as a CMOV, or select function for a SIMD operation. When considering branches inside transforms, it's best to compare to existing implementations of stream processing such as graphics card shaders or compute kernels.
In predication, flow control statements are not ignored, but they are used instead as an indicator of how to merge two results. When the flow control is not based on a constant, a predicated if will generate code that will run both sides of the branch at the same time and discard one result based on the value of the condition. It manages this by selecting one of the results based on the condition. As mentioned before, in many CPUs there is an intrinsic for this, but all CPUs can use bit masking to effect this trick.
SIMD or single-instruction-multiple-data allows the parallel processing of data when the instructions are the same. The data is different but local. When there are no conditionals, SIMD operations are simple to implement on your transforms. In MIMD, that is multiple instructions, multiple data, every piece of data can be operated on by a different set of instructions. Each piece of data can take a different path. This is the simplest and most error-prone to code for because it's how most parallel programming is currently done. We add a thread and process some more data with a separate thread of execution. MIMD includes multi-core general purpose CPUs. It often allows shared memory access and all the synchronisation issues that come with it. It is by far the easiest to get up and running, but it is also the most prone to the kind of rare fatal error caused by complexity of state. Because the order of operations become non-deterministic, the number of different possible routes taken through the code explode super-exponentially.
When you study compression technology, one of the most important aspects you have to understand is the difference between data and information. There are many ways to store information in systems, from literal strings that can be parsed to declare something exists, right down to something simple like a single bit flag to show that a thing might have an attribute. Examples include the text that declares the existence of a local variable in a scripting language, or the bit field containing all the different collision types a physics mesh will respond to. Sometimes we can store even less information than a bit by using advanced algorithms such as arithmetic encoding, or by utilising domain knowledge. Domain knowledge normalisation applies in most game development, but it is increasingly infrequently applied, as many developers are falling foul to overzealous application of quoting premature optimisation. As information is encoded in data, and the amount of information encoded can be amplified by domain knowledge, it's important that we begin to see that the advice offered by compression techniques is: what we are really encoding is probabilities.
If we take an example, a game where the entities have health, regenerate after a while of not taking damage, can die, can shoot each other, then let's see what domain knowledge can do to reduce processing.
We assume the following domain knowledge:
![\begin{linespread}{0.75}\lstinputlisting[language=C,caption={basic entity approach},label=src:EBP_healthnaive]{src/EBP_basehealth.cpp}\end{linespread}](img11.png)
![\begin{linespread}{0.75}\lstinputlisting[language=C,caption={simple health regen},label=src:EBP_healthnaiveregen]{src/EBP_basehealthregen.cpp}\end{linespread}](img12.png)
If we have a list for the entities such as in listing
![]() , then we see the normal problem of data potentially
causing cache line utilisation issues, but aside from that, we can see how you
might run an update function over the list, such as in listing
, then we see the normal problem of data potentially
causing cache line utilisation issues, but aside from that, we can see how you
might run an update function over the list, such as in listing
![]() , which will run for every entity in the game,
every update.
, which will run for every entity in the game,
every update.
We can make this better by looking at the flow control statement. The function won't run if health is at max. It won't run if the entity is dead. The regenerate function only needs to run if it has been long enough since the last damage dealt. All these things considered, regeneration isn't the common case. We should try to organise the data layout for the common case.
![\begin{linespread}{0.75}\lstinputlisting[language=C,caption={Existential processing style health},label=src:EBP_health]{src/EBP_health.cpp}\end{linespread}](img13.png)
Let's change the structures to those in listing ![]() and then
we can run the update function over the health table rather than the entities.
This means we already know, as soon as we are in this function, that the
entity is not dead, and they are hurt.
and then
we can run the update function over the health table rather than the entities.
This means we already know, as soon as we are in this function, that the
entity is not dead, and they are hurt.
![\begin{linespread}{0.75}\lstinputlisting[language=C,caption={every entity health regen},label=src:EBP_healthregen]{src/EBP_healthregen.cpp}\end{linespread}](img14.png)
We only add a new entityhealth element when an entity takes damage. If an entity takes damage when it already has an entityhealth element, then it can update the health rather than create a new row, also updating the time damage was last dealt. If you want to find out someone's health, then you only need to look and see if they have an entityhealth row, or if they have a row in deadEntities table. The reason this works is, an entity has an implicit boolean hidden in the row existing in the table. For the entityDamages table, that implicit boolean is the isHurt variable from the first function. For the deadEntities table, the boolean of isDead is now implicit, and also implies a health value of 0, which can reduce processing for many other systems. If you don't have to load a float and check it is less than 0, then you're saving a floating point comparison or conversion to boolean.
This eradication of booleans is nothing new, because every time you have a pointer to something you introduce a boolean of having a non-NULL value. It's the fact that we don't want to check for NULL which pushes us towards finding a different representation for the lack of existence of an object to process.
Other similar cases include weapon reloading, oxygen levels when swimming,
anything which has a value that runs out, has a maximum, or has a minimum. Even
things like driving speeds of cars. If they are traffic, then they will spend
most of their time driving at traffic speed not some speed they need
to calculate. If you have a group of people all heading in the same direction,
then someone joining the group can be intercepting until they manage to,
at which point they can give up their independence, and become controlled by
the group. There is more on this point in chapter ![]() .
.
By moving to keeping lists of attribute state, you can introduce even more performance improvements. The first thing you can do for attributes that are linked to time is to put them in a sorted list, sorted by time of when they should be acted upon. You could put the regeneration times in a sorted list and pop entityDamage elements until you reach one that can't be moved to the active list, then run through all the active list in one go, knowing they have some damage, aren't dead, and can regen as it's been long enough.
Another aspect is updating certain attributes at different time intervals. Animals and plants react to their environment through different mechanisms. There are the very fast mechanisms such as reactions to protect us from danger. Pulling your hand away from hot things, for example. There are the slower systems too, like the rationalising parts of the brain. Some, apparently quick enough that we think of them as real-time, are the quick thinking and acting processes we consider to be the actions taken by our brains when we don't have time to think about things in detail, such as catching a ball or balancing a bicycle. There is an even slower part of the brain, the part that isn't so much reading this book, but is consuming the words, and making a model of what they mean so as to digest them. There is also the even slower systems, the ones which react to stress, chemical levels spread through the body as hormones, or just the amount of sugar you have available, or current level of hydration. An AI which can think and react on multiple time-scales is more likely to waste fewer resources, but also much less likely to act oddly, or flip-flop between their decisions. Committing to doing an update of every system every frame could land you in an impossible situation. Splitting the workload into different update rates can still be regular, but offers a chance to balance the work over multiple frames.
Another use is in state management. If an AI hears gunfire, then they can add a row to a table for when they last heard gunfire, and that can be used to determine whether they are in a heightened state of awareness. If an AI has been involved in a transaction with the player, it is important they remember what has happened as long as the player is likely to remember it. If the player has just sold an AI their +5 longsword, it's very important the shopkeeper AI still have it in stock if the player just pops out of the shop for a moment. Some games don't even keep inventory between transactions, and that can become a sore point if they accidentally sell something they need and then save their progress.
From a gameplay point of view, these extra bits of information are all about how the world and player interact. In some games, you can leave your stuff lying around forever, and it will always remain just how you left it. It's quite a feat that all the things you have dumped in the caves of some open-world role-playing games, are still hanging around precisely where you left them hours and hours ago.
The general concept of tacking on data, or patching loaded data with dynamic additional attributes, has been around for quite a while. Save games often encode the state of a dynamic world as a delta from the base state, and one of the first major uses was in fully dynamic environments, where a world is loaded, but can be destroyed or altered later. Some world generators took a procedural landscape and allowed their content creators to add patches of extra information, villages, forts, outposts, or even break out landscaping tools to drastically adjust the generated data.
Enumerations are used to define sets of states. We could have had a state variable for the regenerating entity, one that had infullhealth, ishurt, isdead as its three states. We could have had a team index variable for the avoidance entity enumerating all the available teams. Instead, we used tables to provide all the information we needed, as there were only two teams. Any enum can be emulated with a variety of tables. All you need is one table per enumerable value. Setting the enumeration is an insert into a table or a migration from one table to another.
When using tables to replace enums, some things become more difficult: finding out the value of an enum in an entity is difficult as it requires checking all the tables which represent that state for the entity. However, the main reason for getting the value is either to do an operation based on an external state or to find out if an entity is in the right state to be considered for an operation. This is disallowed and unnecessary for the most part, as firstly, accessing external state is not valid in a pure function, and secondly, any dependent data should already be part of the table element.
If the enum is a state or type enum previously handled by a switch or virtual call, then we don't need to look up the value, instead, we change the way we think about the problem. The solution is to run transforms taking the content of each of the switch cases or virtual methods as the operation to apply to the appropriate table, the table corresponding to the original enumeration value.
If the enum is instead used to determine whether or not an entity can be operated upon, such as for reasons of compatibility, then consider an auxiliary table to represent being in a compatible state. If you're thinking about the case where you have an entity as the result of a query and need to know if it is in a certain state before deciding to commit some changes, consider that the compatibility you seek could have been part of the criteria for generating the output table in the first place, or a second filtering operation could be committed to create a table in the right form.
In conclusion, the reason why you would put an enum in table form, is to reduce control flow impact. Given this, it's when we aren't using the enumerations to control instruction flow that it's fine to leave them alone. Another possibility is when the value of the enum changes with great frequency, as moving objects from table to table has a cost too.
Examples of enumerations that make sense are keybindings, enumerations of colours, or good names for small finite sets of values. Functions that return enums, such as collision responses (none, penetrating, through). Any kind of enumeration which is actually a lookup into data of another form is good, where the enum is being used to rationalise the access to those larger or harder to remember data tables. There is also a benefit to some enums in that they will help you trap unhandled cases in switches, and to some extent, they are a self-documenting feature in most languages.
Let's consider now how we implement polymorphism. We know we don't have to use a virtual table pointer; we could use an enum as a type variable. That variable, the member of the structure that defines at runtime what that structure should be capable of and how it is meant to react. That variable will be used to direct the choice of functions called when methods are called on the object.
When your type is defined by a member type variable, it's usual to implement virtual functions as switches based on that type, or as an array of functions. If we want to allow for runtime loaded libraries, then we would need a system to update which functions are called. The humble switch is unable to accommodate this, but the array of functions could be modified at runtime.
We have a solution, but it's not elegant, or efficient. The data is still in charge of the instructions, and we suffer the same instruction cache misses and branch mispredictions as whenever a virtual function is unexpected. However, when we don't really use enums, but instead tables that represent each possible value of an enum, it is still possible to keep compatible with dynamic library loading the same as with pointer based polymorphism, but we also gain the efficiency of a data-flow processing approach to processing heterogeneous types.
For each class, instead of a class declaration, we have a factory that produces the correct selection of table insert calls. Instead of a polymorphic method call, we utilise existential processing. Our elements in tables allow the characteristics of the class to be implicit. Creating your classes with factories can easily be extended by runtime loaded libraries. Registering a new factory should be simple as long as there is a data-driven factory method. The processing of the tables and their update() functions would also be added to the main loop.
If you create your classes by composition, and you allow the state to change by inserting and removing from tables, then you also allow yourself access to dynamic runtime polymorphism. This is a feature normally only available when dynamically responding via a switch.
Polymorphism is the ability for an instance in a program to react to a common entry point in different ways due only to the nature of the instance. In C++, compile-time polymorphism can be implemented through templates and overloading. Runtime polymorphism is the ability for a class to provide a different implementation for a common base operation with the class type unknown at compile-time. C++ handles this through virtual tables, calling the right function at runtime based on the type hidden in the virtual table pointer at the start of the memory pointed to by the this pointer. Dynamic runtime polymorphism is when a class can react to a common call signature in different ways based on its type, but its type can change at runtime. C++ doesn't implement this explicitly, but if a class allows the use of an internal state variable or variables, it can provide differing reactions based on the state as well as the core language runtime virtual table lookup. Other languages which define their classes more fluidly, such as Python, allow each instance to update how it responds to messages, but most of these languages have very poor general performance as the dispatch mechanism has been built on top of dynamic lookup.
![\begin{linespread}{0.75}\lstinputlisting[language=C,caption={simple object-oriented shape code},label=src:ooshape]{src/EBP_ooshape.cpp}\end{linespread}](img15.png)
Consider the code in listing ![]() , where we expect the runtime
method lookup to solve the problem of not knowing the type but wanting
the size. Allowing the objects to change shape during their lifetime requires
some compromise. One way is to keep a type variable inside the class such as in listing
, where we expect the runtime
method lookup to solve the problem of not knowing the type but wanting
the size. Allowing the objects to change shape during their lifetime requires
some compromise. One way is to keep a type variable inside the class such as in listing ![]() , where the object acts as a container for the type variable, rather than as an instance of a specific shape.
, where the object acts as a container for the type variable, rather than as an instance of a specific shape.
![\begin{linespread}{0.75}\lstinputlisting[language=C,caption={ugly internal type code},label=src:shapetype]{src/EBP_shapetype.cpp}\end{linespread}](img16.png)
A better way is to have a conversion function to handle each case. In listing
![]() we see how that can be achieved.
we see how that can be achieved.
![\begin{linespread}{0.75}\lstinputlisting[language=C,caption={convert existing class to new class},label=src:shapechange]{src/EBP_shapechange.cpp}\end{linespread}](img17.png)
Though this works, all the pointers to the old class are now invalid. Using handles would mitigate these worries, but add another layer of indirection in most cases, dragging down performance even further.
If you use existential processing techniques, your classes defined by the tables they belong to, then you can switch between tables at runtime. This allows you to change behaviour without any tricks, without the complexity of managing a union to carry all the different data around for all the states you need. If you compose your class from different attributes and abilities then need to change them post creation, you can. If you're updating tables, the fact that the pointer address of an entity has changed will mean little to you. It's normal for an entity to move around memory in table-based processing, so there are fewer surprises. Looking at it from a hardware point of view, in order to implement this form of polymorphism you need a little extra space for the reference to the entity in each of the class attributes or abilities, but you don't need a virtual table pointer to find which function to call. You can run through all entities of the same type increasing cache effectiveness, even though it provides a safe way to change type at runtime.
Via the nature of having classes defined implicitly by the tables they belong to, there is an opportunity to register a single entity with more than one table. This means that not only can a class be dynamically runtime polymorphic, but it can also be multi-faceted in the sense that it can be more than one class at a time. A single entity might react in two different ways to the same trigger call because it might be appropriate for the current state of that class.
This kind of multidimensional classing doesn't come up much in traditional gameplay code, but in rendering, there are usually a few different axes of variation such as the material, what blend mode, what kind of skinning or other vertex adjustments are going to take place on a given instance. Maybe we don't see this flexibility in gameplay code because it's not available through the natural tools of the language. It could be that we do see it, but it's what some people call entity component systems.
When you wanted to listen for events in a system in the old days, you'd attach yourself to an interrupt. Sometimes you might get to poke at code that still does this, but it's normally reserved for old or microcontroller scale hardware. The idea was simple, the processor wasn't really fast enough to poll all the possible sources of information and do something about the data, but it was fast enough to be told about events and process the information as and when it arrived. Event handling in games has often been like this, register yourself as interested in an event, then get told about it when it happens. The publish and subscribe model has been around for decades, but there's no standard interface built for it in some languages and too many standards in others. As it often requires some knowledge from the problem domain to choose the most effective implementation.
Some systems want to be told about every event in the system and decide for themselves, such as Windows event handling. Some systems subscribe to very particular events but want to react to them as soon as they happen, such as handlers for the BIOS events like the keyboard interrupt. The events could be very important and dispatched directly by the action of posting the event, such as with callbacks. The events could be lazy, stuck in a queue somewhere waiting to be dispatched at some later point. The problem they are trying to solve will define the best approach.
Using your existence in a table as the registration technique makes this simpler than before and lets you register and de-register with great pace. Subscription becomes an insert, and unsubscribing a delete. It's possible to have global tables for subscribing to global events. It would also be possible to have named tables. Named tables would allow a subscriber to subscribe to events before the publisher exists.
When it comes to firing off events, you have a choice. You can choose to fire off the transform immediately, or queue up new events until the whole transform is complete, then dispatch them all in one go. As the model becomes simpler and more usable, the opportunity for more common use leads us to new ways of implementing code traditionally done via polling.
For example: unless a player character is within the distance to activate a door, the event handler for the player's action button needn't be attached to anything door related. When the character comes within range, the character registers into the has_pressed_action event table with the open_door_(X) event result. This reduces the amount of time the CPU wastes figuring out what thing the player was trying to activate, and also helps provide state information such as on-screen displays saying pressing Green will Open the door.
If we allow for all tables to have triggers like those found in DBMSs, then it may be possible to register interest in changes to input mappings, and react. Hooking into low-level tables such as a insert into a has_pressed_action table would allow user interfaces to know to change their on-screen display to show the new prompt.
This coding style is somewhat reminiscent of aspect-oriented programming where it is easy to allow for cross-cutting concerns in the code. In aspect-oriented programming, the core code for any activities is kept clean, and any side effects or vetoes of actions are handled by other concerns hooking into the activity from outside. This keeps the core code clean at the expense of not knowing what is really going to be called when you write a line of code. How using registration tables differs is in where the reactions come from and how they are determined. Debugging can become significantly simpler as the barriers between cause and effect normally implicit in aspect-oriented programming are significantly diminished or removed, and the hard to adjust nature of object-oriented decision making can be softened to allow your code to become more dynamic without the normally associated cost of data-driven control flow.
Online release of Data-Oriented Design :